Decision Tree is a supervised machine learning algorithm that helps break down decisions into simple steps and shows possible outcomes in a tree-like structure. Auxin Security improves the adoption of AI and machine learning technologies by integrating strong security and compliance measures into the data science workflow.
With solutions customized for industries such as finance, healthcare, and defense, Auxin Security ensures that sensitive data and AI applications remain protected from evolving threats, allowing organizations to focus on advancement and operational efficiency.
A Decision Tree works by splitting data into smaller parts based on different features, and creating a structure with root nodes, branches, and leaf nodes that represent final decisions. It is widely used for tasks like organizing data into categories or predicting numbers because it is easy to understand and works with various types of data.
Decision trees are utilized in real-world scenarios where transparent, step-by-step decision-making is beneficial. Similar to banks deciding whether a customer should receive a loan based on their income and credit history, doctors diagnosing diseases from symptoms, or companies predicting customer buying behavior. These examples demonstrate how decision trees handle various types of data and facilitate transparent decision-making.
In this blog, we will show you how to run a Decision Tree quickly and easily in just five minutes using Google Colab.
The Decision Tree Algorithm
The Decision Tree algorithm works like a flowchart, where each internal node represents a specific feature or attribute, each branch represents a decision made based on that feature, and each leaf node indicates the final outcome. The highest point in the tree is called the root node, which divides the data according to a chosen feature’s value.
This division process repeats multiple times, a process known as recursive partitioning. Due to its flowchart-like design, a decision tree is straightforward to follow and understand, much like how people naturally make decisions one step at a time. This clear structure makes decision trees easy to interpret.
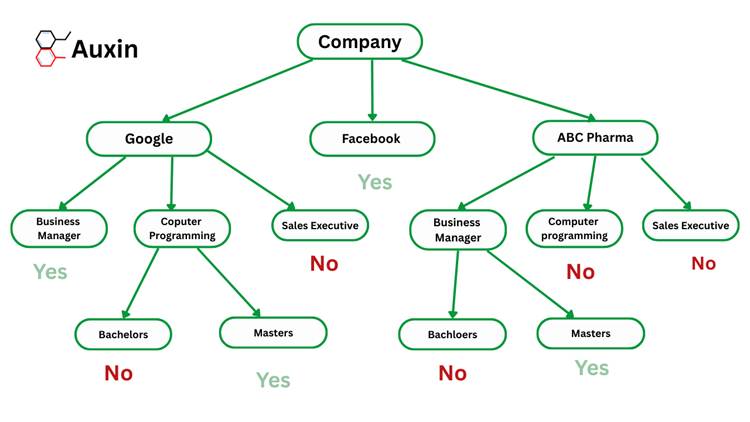
How does the Decision Tree Algorithm work?
The decision tree algorithm works through these main steps:
- First, it uses Attribute Selection Measures (ASM) to identify the feature that best splits the data.
- This chosen feature becomes a decision node, splitting the data into smaller groups.
- The process continues repeating for each subgroup until one of the following happens:
- All data points in a group share the same attribute value.
- There are no remaining features left to split on.
- There are no more data points to divide.
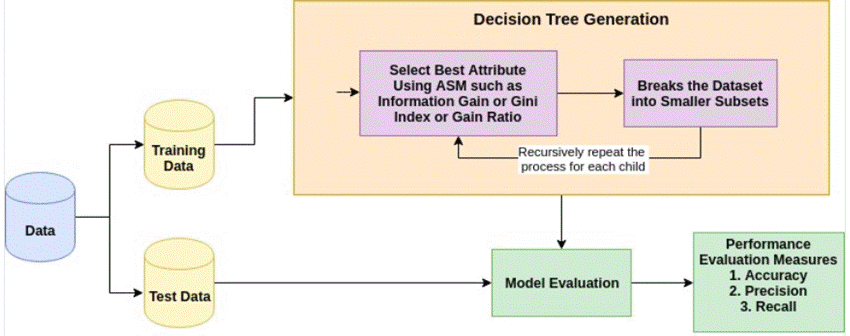
Attribute Selection Measures
Attribute Selection Measures (ASMs) help decide which feature to split the data in a decision tree at each step. They rank features based on how well they separate the data. The most common ASMs are Information Gain, Gain Ratio, and Gini Index.
- Information Gain
Information Gain measures the clarity gained when a feature splits data and reduces uncertainty. It picks the feature that gives the highest reduction in impurity.
- Gain Ratio
Gain Ratio improves information gain by fixing its bias toward features with many distinct values. It normalizes information gain to avoid choosing features like unique IDs that don’t help with meaningful splits.
- Gini Index
The Gini Index assesses the probability of mislabeling a random element based on the label distribution in a subset. It prefers splits that create pure groups and is used in the Classification and Regression Trees (CART) algorithm.
Carly Fiorina, an American businesswoman and former CEO of HP, stated that:
“The goal is to transform data into infromoation, and information into insight.”
This quote highlights the primary purpose behind utilizing machine learning tools like the Gini Index. The Gini Index helps sort and organize raw data, transforming it into clear information that can be used to make informed decisions. This method collects data but transforms it into actionable insights that guide real-world actions and results.
Implementing Decision Trees in Python
In this example, we will use the public salaries.csv dataset, which contains information about companies, job roles, and salaries. Based on features such as company and job title, we will construct a decision tree to predict whether a job offers a salary above $100,000.
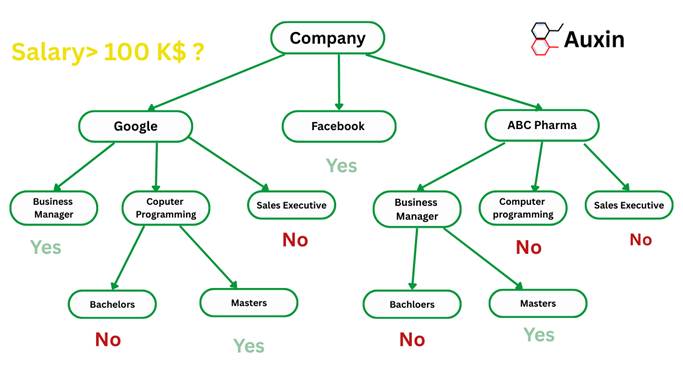
Setting up your system
For this project, I used Google Colab, a free online platform, to create and run Python notebooks. Here’s a step-by-step guide to setting up and using Google Colab to run your code smoothly.
Step 1: Import Required Libraries
Import essential libraries for data handling, visualization, and machine learning tasks.
import pandas as pd
from sklearn.tree import DecisionTreeClassifier # Import Decision Tree Classifier
from sklearn.model_selection import train_test_split # Import train_test_split function
from sklearn import metrics #Import scikit-learn metrics module for accuracy calculationStep 2: Load the Dataset
Download the dataset from here, upload it to your notebook, and read it into the pandas dataframe.
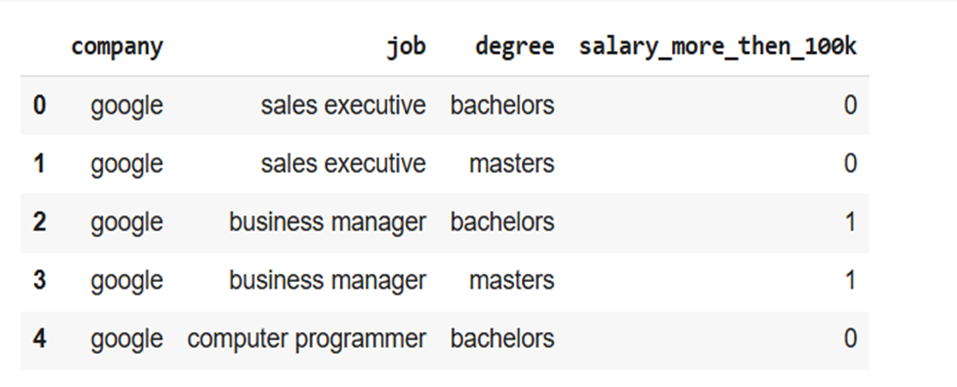
df = pd.read_csv("salaries.csv")
df.head()
Step 3: Prepare Input Features
Remove the target column from the dataset, keeping only input features for the model.
inputs = df.drop('salary_more_then_100k', axis='columns')Step 4: Define Target Variable
Select the target column that the model will learn to predict.
target = df['salary_more_then_100k']Step 5: Initialize Label Encoders
Set up label encoders to convert categorical text data into numeric form.
from sklearn.preprocessing import LabelEncoder
le_company = LabelEncoder()
le_job = LabelEncoder()
le_degree = LabelEncoder()Step 6: Encode Categorical Features
Transform categorical columns into numeric values and add them as new columns.
inputs['company_n'] = le_company.fit_transform(inputs['company'])
inputs['job_n'] = le_job.fit_transform(inputs['job'])
inputs['degree_n'] = le_degree.fit_transform(inputs['degree'])
inputs
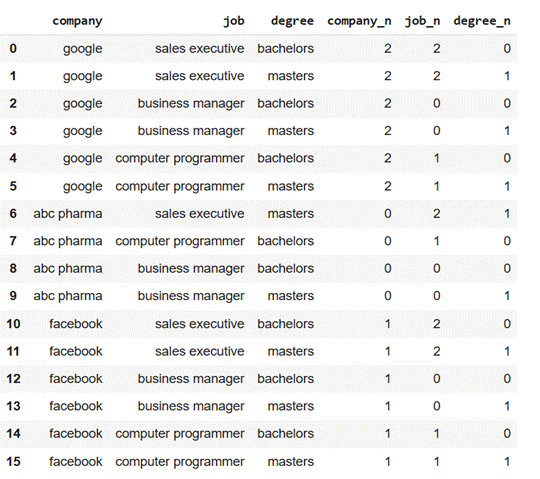
Step 7: Drop Original Categorical Columns
Remove the original text columns, keeping only the encoded numeric features.
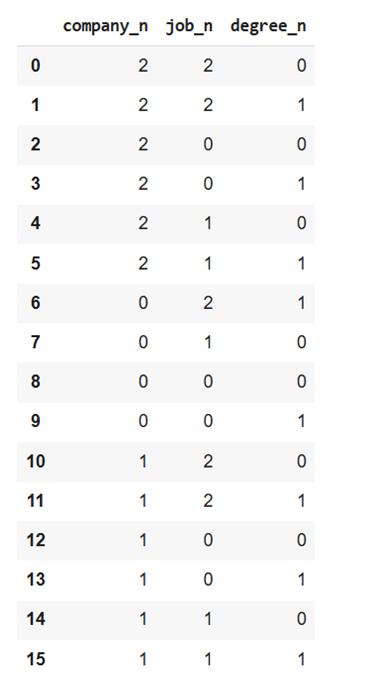
inputs_n = inputs.drop(['company', 'job', 'degree'], axis='columns')
inputs_n
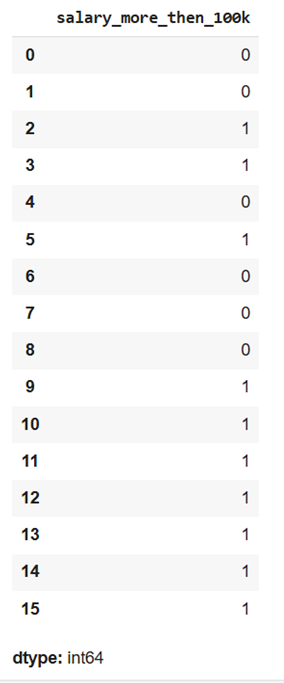
target
Step 8: Train the model
Initialize the decision tree classifier for training. Training a machine learning model involves using a dataset to estimate the model’s parameters. The training process iteratively updates the model parameters, minimizing a loss function that measures the difference between the predicted values and the actual values in the training data, and updates the model parameters to improve the model’s accuracy.
from sklearn import tree
model = tree.DecisionTreeClassifier()
model.fit(inputs_n, target)
Step 10: Evaluate Model Accuracy
Check how well the model predicts the target on the training data.
model.score(inputs_n, target)
Step 11: Predict result / Score Model
Once the model is trained, it can be used to make predictions on new data. The prediction is made by starting at the root node of the tree and navigating it based on the attribute values of the input sample. The prediction is given by the class label at the leaf node reached.
The accuracy of the model can be evaluated on a test set, which was previously held out from the training process.
model.predict([[2, 1, 0]])Complete the Code at the Auxin GitHub
You can get the entire code and the notebook from our Auxin GitHub page.
Let’s sum up
Decision Trees make it easy to turn complex data into simple, clear decisions for any industry. Our step-by-step tutorial can help teams understand and trust predictions for finance, healthcare, or retail. With Auxin Security, your data remains protected while you develop innovative AI solutions, ensuring both safe and efficient decision-making.