“AI is the new electricity,” according to the famous computer scientist Andrew Ng, a pioneer in AI research and education. In the same way electricity revolutionized the modern world, this quote shows how AI is becoming essential across industries. But just as electricity needs a stable grid, AI needs up-to-date information to work well, a problem this blog thoroughly addresses.
According to Gartner, by 2026, nearly 60% of AI projects will risk failing because of inadequate or poorly managed data integration, and over 60% of organizations will have trouble managing AI-ready data. Furthermore, over 60% of users complain about AI hallucinations, in which models generate false or misleading responses. These statistics highlight a pervasive difficulty in providing timely and accurate AI responses, which is essential as AI becomes increasingly incorporated into daily applications.
Large language models have transformed natural language understanding, but their reliance on static, pre-trained knowledge frequently prevents them from offering current and accurate data. This difference compromises user trust and limits AI’s effectiveness in essential sectors like healthcare, law, and finance, where current and verifiable expertise is crucial. These models maintain the risk of producing inaccurate or outdated results without new data, which would diminish their value.
This is addressed by Retrieval Augmented Generation (RAG), which allows AI systems to generate text while concurrently retrieving pertinent data from outside sources. This combination of retrieval and generation reduces errors and hallucinations by developing accurate and contextually relevant responses.
RAG architectures are becoming increasingly crucial for creating AI that can deliver accurate, dependable insights across various domains and keep up with the explosive growth of knowledge.
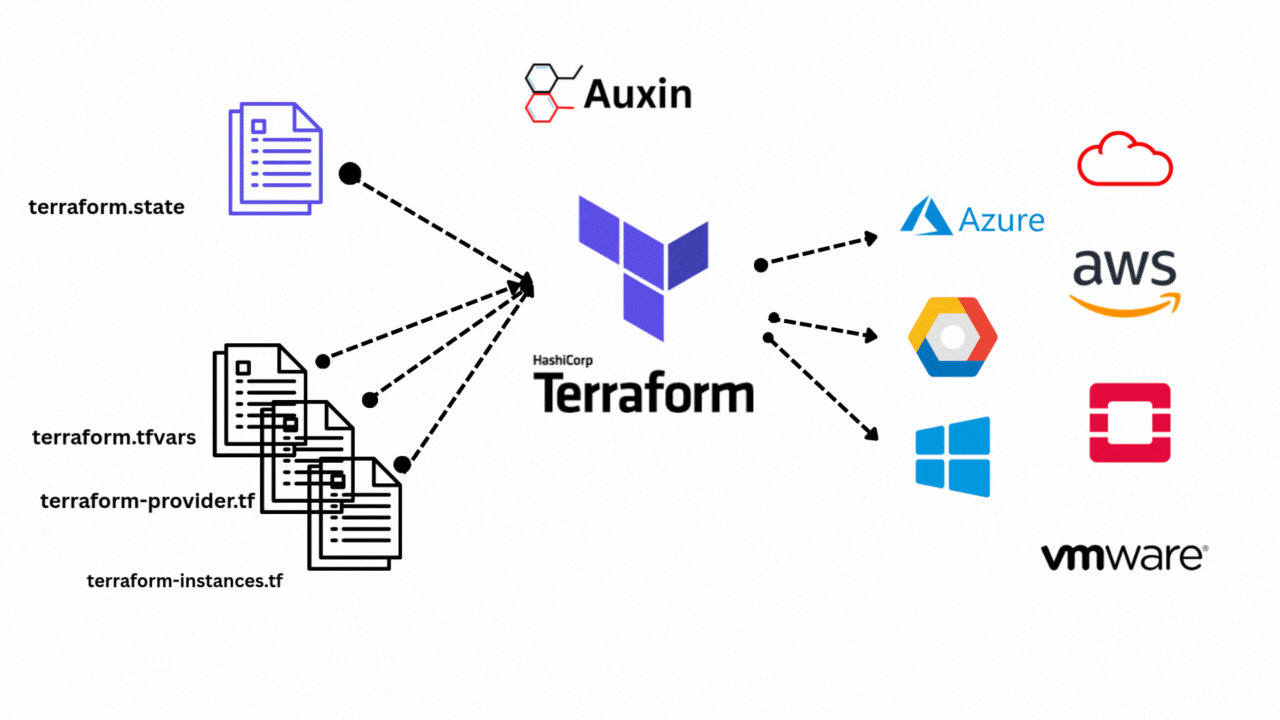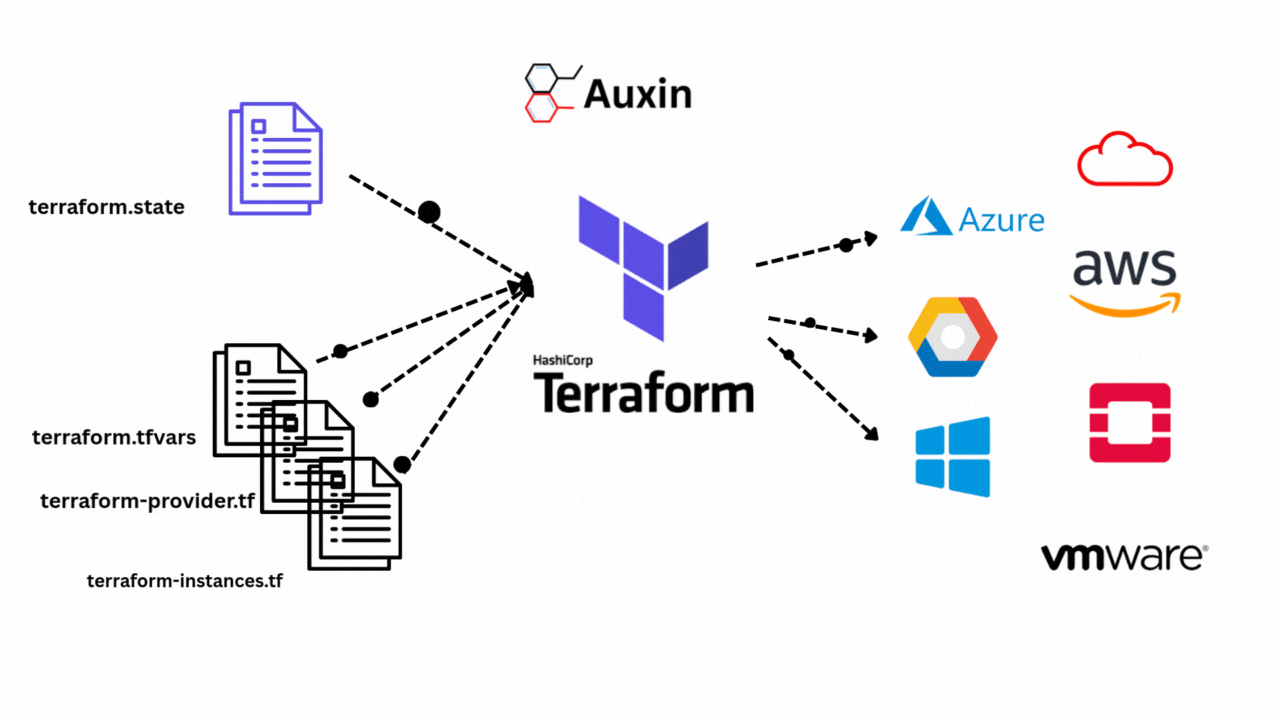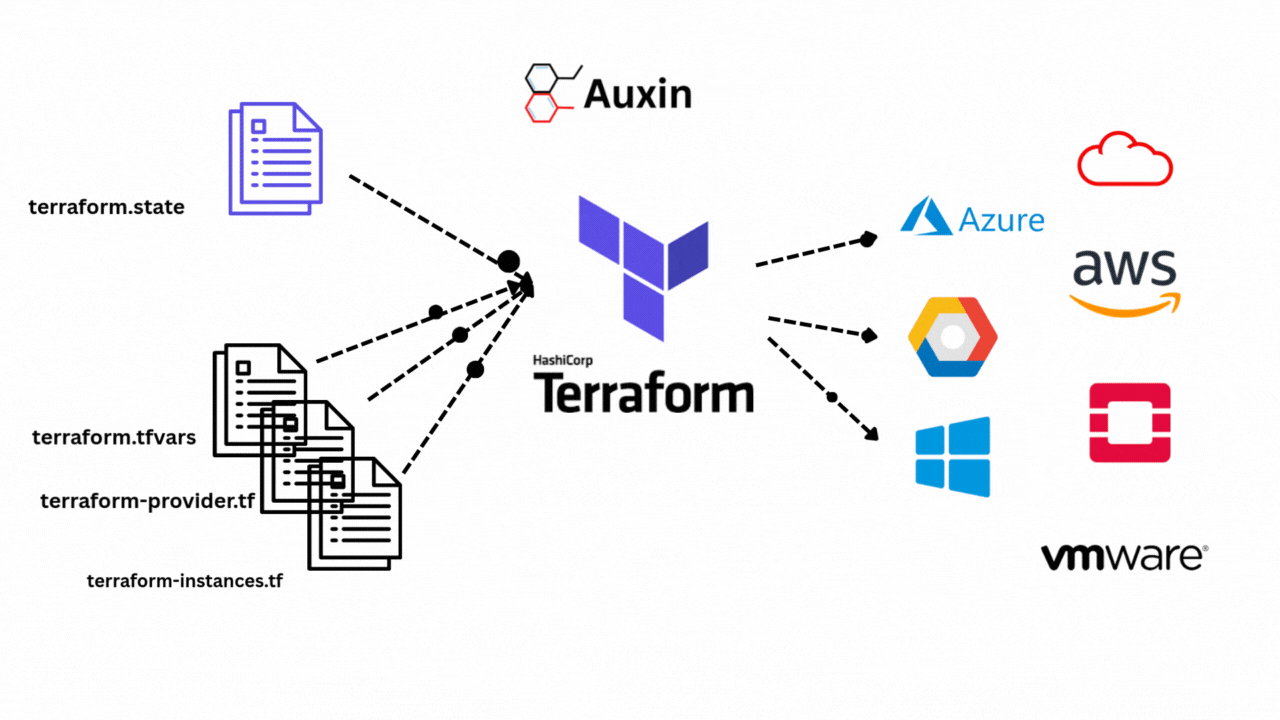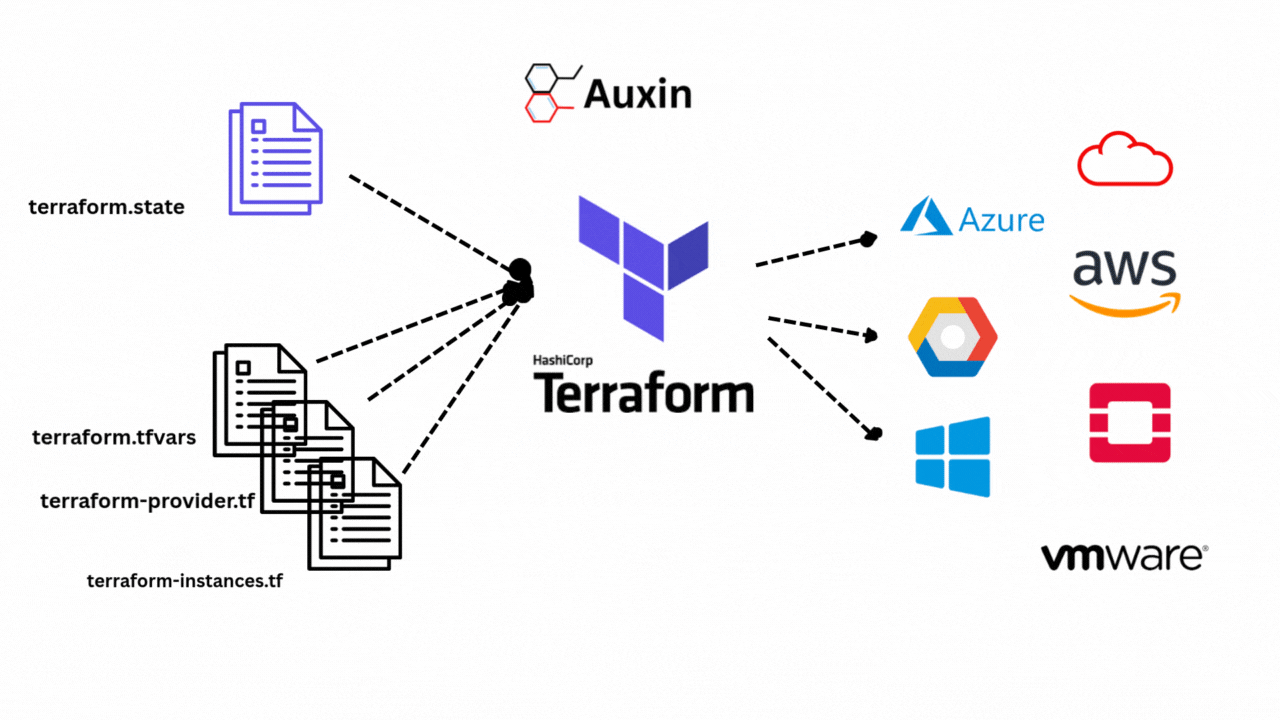
By integrating generative models and retrieval systems, RAG improves artificial intelligence. During query processing, RAG dynamically retrieves pertinent documents or data from external sources rather than depending exclusively on internal knowledge. The retrieved information makes the generated responses more factual and contextually aware.
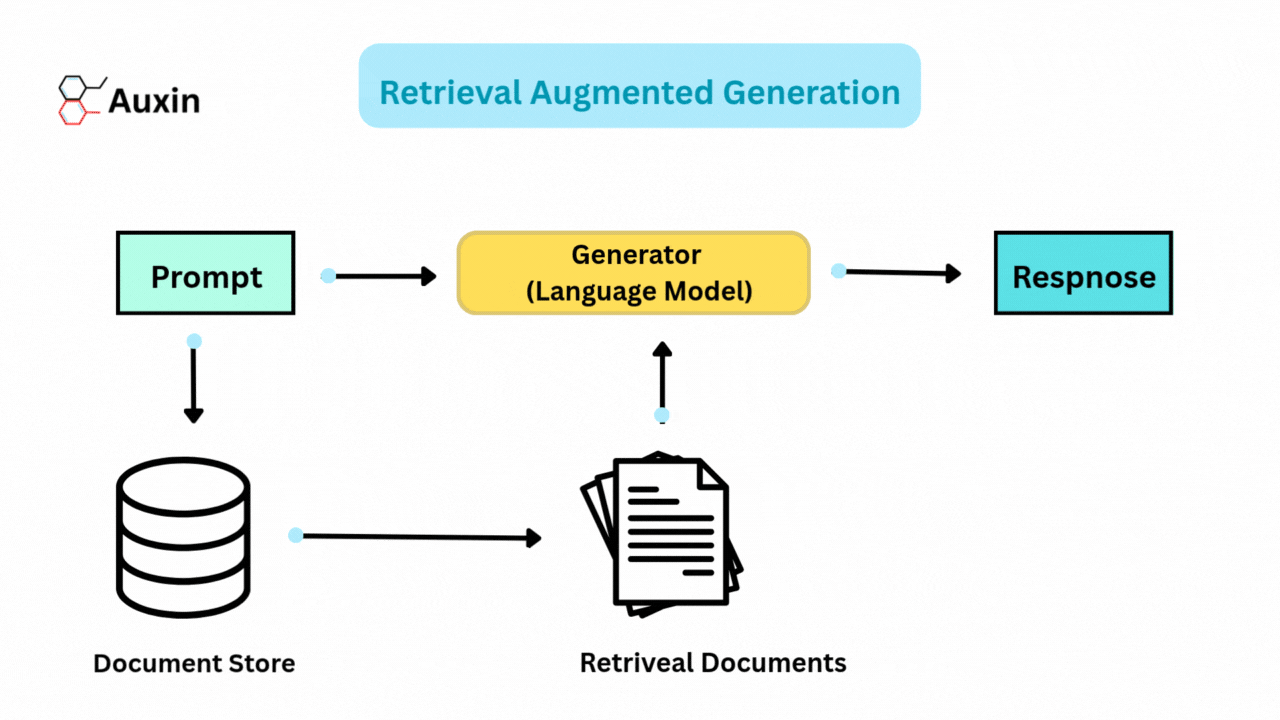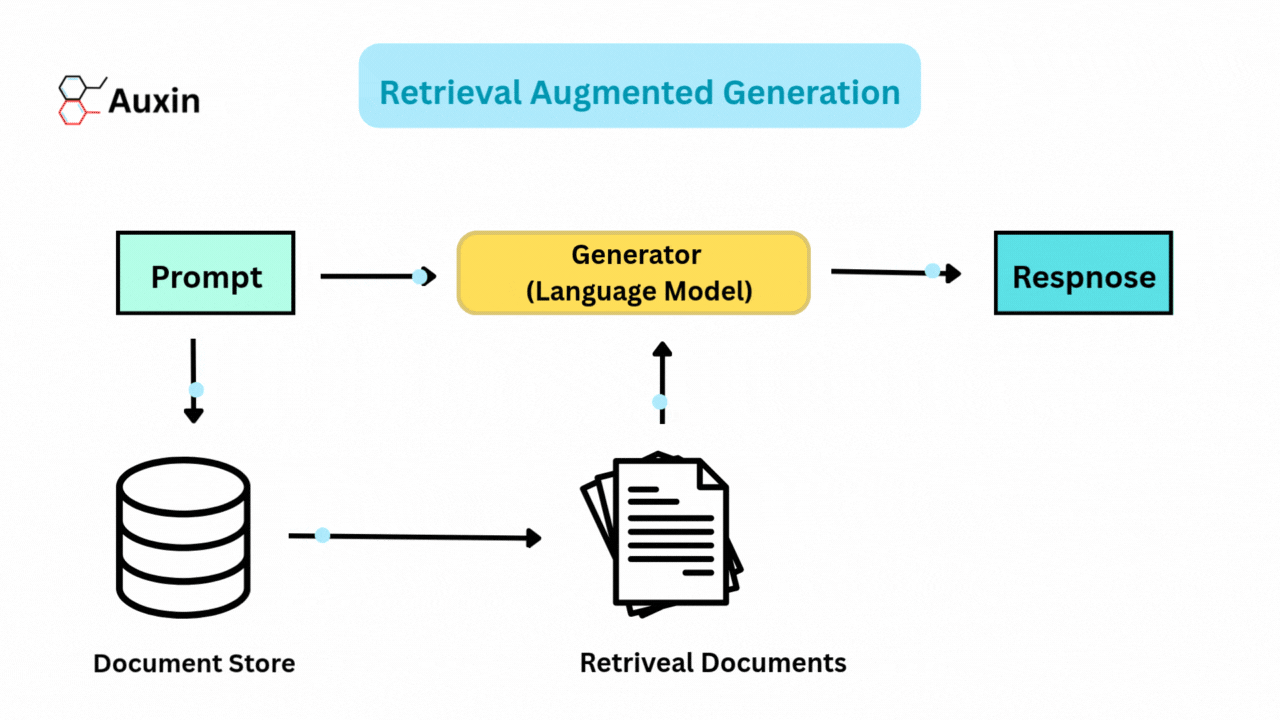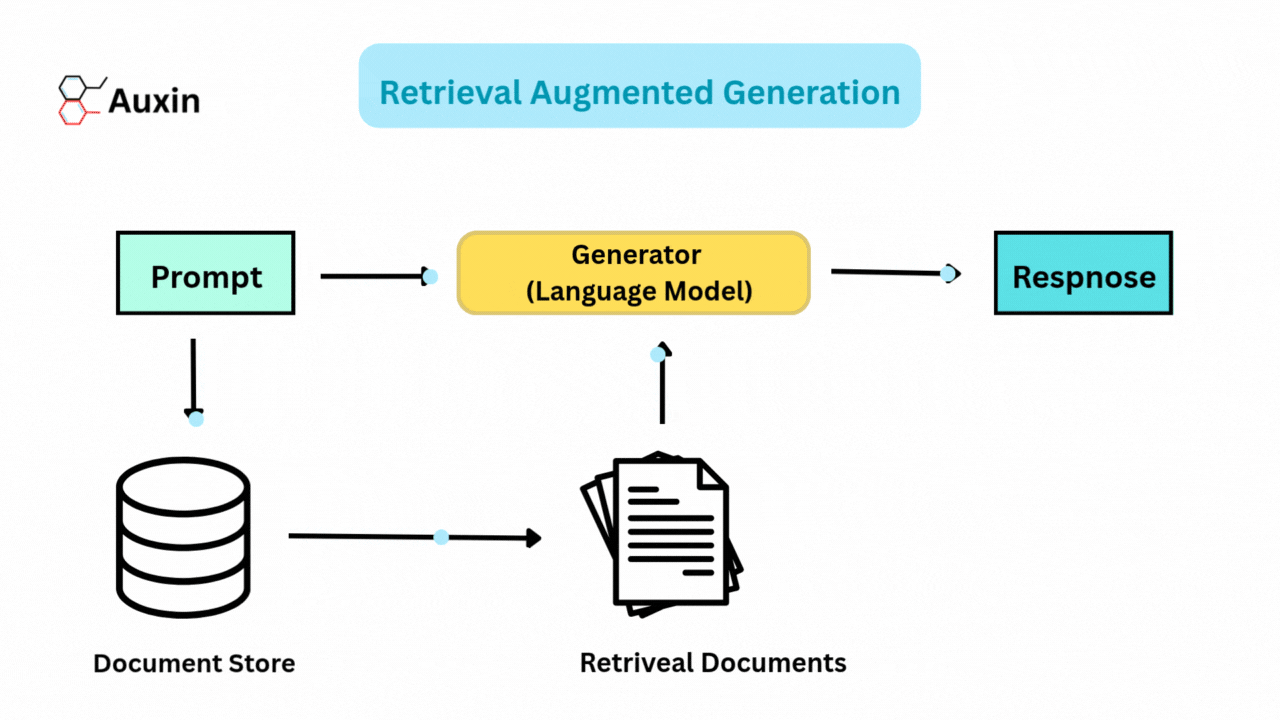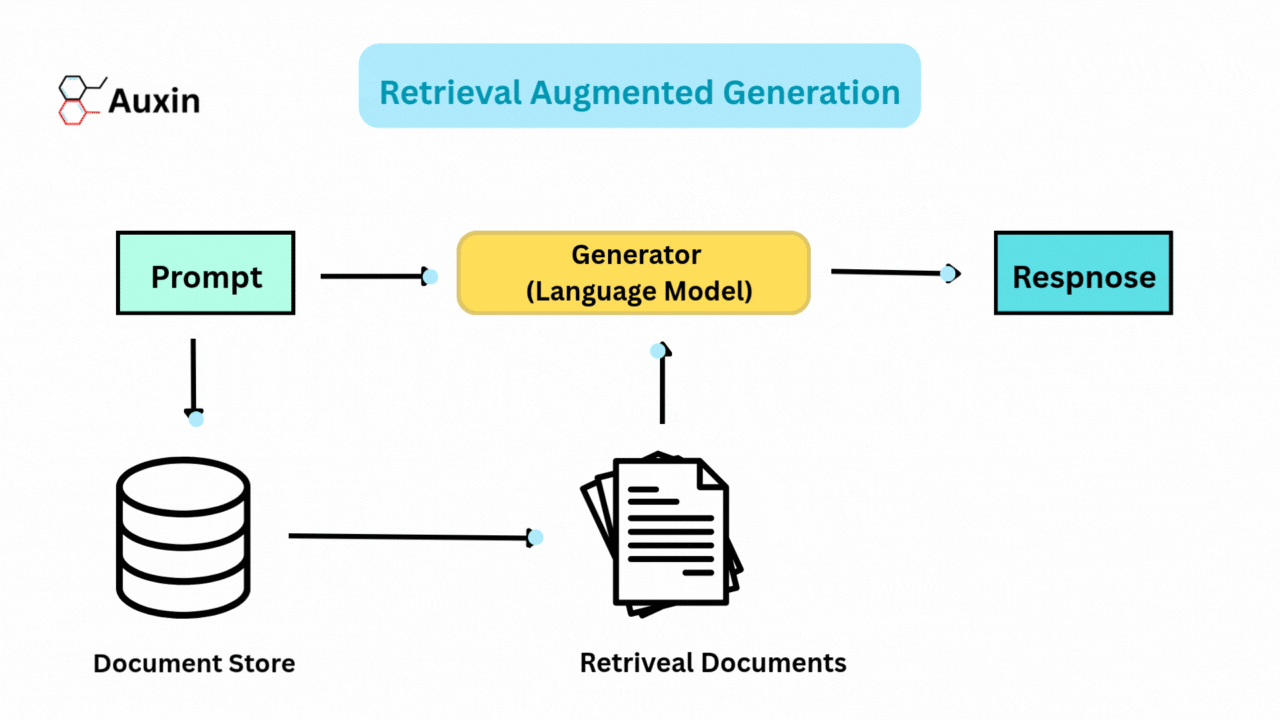
The rise of RAG made frameworks like Haystack and LlamaIndex easier to build scalable pipelines. Advancements further improve RAG’s capabilities in hybrid retrieval, multimodal integration, and agentic systems, enabling it to adjust to intricate real-world requirements.
Auxin Security ensures that AI deployments are secure and scalable by offering customized consultation in cloud solutions architecture and container security. When combined, these solutions enable businesses to create context-rich, accurate, and dependable AI experiences that keep up with the changing information environment of 2025.
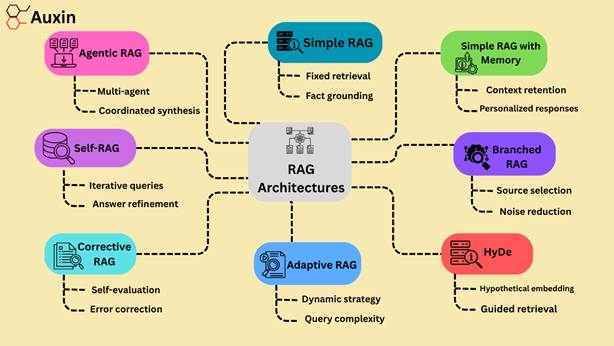
How RAG Works
Retrieval Augmented Generation (RAG) combines text generation and real-time information retrieval to improve language models. This method enhances accuracy, relevance, and adaptability across various applications by using distinct architectural designs to address particular challenges.
The table below outlines eight major RAG architectures, along with the issues they address, common use cases, methods they employ, and sectors they respond to.
| Challenges / Problem faced | Use Cases | Architecture Overview | Industry |
| Prevent Hallucination or Working with Custom/Domain-Specific Ddta, Improving Factual Accuracy | Ideal for customer service bots and FAQ systems that need precise responses from a small collection of known documents. | Simple RAG: When a user query is received, data is retrieved from a static database, and a response is produced. using the information retrieved. | Small-scale knowledge bases, product support, and customer service. |
| Maintaining Context, Enhancing Multi-Turn Conversations | Beneficial for personalized recommendation engines that rely on past data and chatbots that must continuously maintain user context. | Simple RAG with Memory: Expands upon Simple RAG by adding a memory component that keeps track of previous interactions. After retrieving external documents and memory, the model generates a response. | Conversational AI, customized marketing, and customer service. |
| Efficient Source Selection, Reducing Irrelevant Data Retrieval | Ideal for specialized knowledge retrieval where source selection is essential, multidisciplinary academic work, and legal research. | Branched RAG: After determining which data source to query, the model analyzes the query, retrieves documents from the source, and uses this information to respond. | Specialized enterprise knowledge management, universities, and legal. |
| Handling Vague Queries, Guiding Retrieval with Hypothetical Context | Suitable for research and development settings and creative content creation, where adaptable, innovative solutions are required. | HyDe: The model creates a hypothetical document embedding to represent an ideal response. Before generating the final output, it retrieves actual documents guided by this embedding. | R&D, Creative Industries, Content Creation |
| Dynamic Retrieval Strategy, Balancing Speed and Depth | Ideal for business search systems that can process various queries, from basic to complex. | Adaptive RAG: The model creates a customized response by dynamically choosing retrieval sources and techniques according to the query’s complexity. | Enterprise, Knowledge Management |
| Improving Retrieval Accuracy, Self-Correcting Errors | It is crucial for fields that demand a high degree of precision, such as financial analysis, medical diagnosis, and legal document drafting. | Corrective RAG (CRAG): Before producing the final response, the model retrieves documents, divides them into smaller knowledge sections, rates each one for relevance, eliminates irrelevant portions, and, if required, conducts additional retrieval. | Healthcare, Legal, Finance |
| Iterative Self-Retrieval, Refining Answers During Generation | Ideal for long-form content production and exploratory research where information needs change as responses are generated. | Self-RAG: Begins with a beginning retrieval determined by the user’s query. The model iteratively generates new retrieval queries to improve the response and realizes gaps during generation. | Research, Content Creation, Academia |
| Autonomous Multi-Agent Coordination, Managing Complex Multi-Source Retrieval | Designed to support executive decision-making that calls for thorough synthesis, automated research, and multi-source data aggregation. | Agentic RAG: It activates several document agents that are in charge of particular documents. A meta-agent coordinates these agents and combines their outputs to create a thorough and cohesive final response. | Enterprise, Executive Support, Data Aggregation |
Looking ahead with RAG
Over 60% of AI projects risk failing by 2025 due to inadequate data integration, highlighting the urgent need for trustworthy AI architectures. Across industries, retrieval-augmented generation is essential for providing precise, up-to-date insights.
To assist businesses in implementing dependable and legal AI solutions, Auxin Security offers professional cybersecurity, DevSecOps, and cloud consulting services. Combined, these developments ensure the safe and efficient development of AI’s potential.