Save Cost and Securely Save MariaDB Backups in S3
Introduction
Data backup is a critical aspect of database management, ensuring that your data is safe and can be restored in case of data loss or system failures. By leveraging the scalability, durability, and cost-effectiveness of Amazon S3 along with the flexibility of EKS, we can create a backup solution that is reliable and secure, providing you with peace of mind about the safety of your data. This blog post will explore how to securely back up MariaDB databases running on Amazon Elastic Kubernetes Service (EKS) to low-cost Amazon S3 storage.
Below is a detailed guide on accomplishing this:
Prerequisites
To proceed, ensure you have both the AWS Command Line Interface (CLI) and Kubernetes Command Line Tool (kubectl) installed. If they’re not already installed, you can easily download them to your system by https://docs.aws.amazon.com/cli/latest/userguide/getting-started-install.html and https://kubernetes.io/docs/tasks/tools/.
Let’s get started!
Before accessing the EKS cluster, it’s essential to configure your AWS account credentials. This ensures proper authentication and authorization for accessing resources within the cluster.
Step 1
Open your Command Prompt or Shell, then execute the command aws configure. When prompted, input your AWS Access Key ID, Secret Access Key, and default region.
Step 2
To establish a connection with the EKS cluster, execute the command and retrieve the AWS region and Cluster name provided within it. These parameters are essential for connecting to the cluster successfully.

Step 3
Execute the provided command to create a backup of the MariaDB database, ensuring data security and integrity through regular backups.
kubectl exec <mariadb-pod-name> -n <namespace> — mysqldump -u <db-username> -p<db-password> <db-name> –routines > <backup-name>.sql
- kubectl exec: Executes a command in a Kubernetes pod.
- <mariadb-pod-name>: Replace with the actual name of your MariaDB pod.
- -n <namespace>: Specifies the namespace where the pod is located.
- –: Separates kubectl options from the command to be executed in the pod.
- mysqldump -u <db-username> -p<db-password> <db-name> –routines: Runs the mysqldump command inside the pod to dump the specified database along with its routines. The –routines option includes stored procedures and functions in the database backup.
- <backup-name>.sql: Redirects the output of the mysqldump command to a SQL file with the specified backup name.
Step 4
After completing the backup process, execute the given command to push the backup file to the designated S3 bucket, ensuring data redundancy and accessibility through AWS S3 storage.
aws s3 cp <backup-name> s3://<bucket-name>/<folder-name>
Step 5
By default, S3 stores objects in a Standard storage class, so your backup will be stored in a standard storage class. You can configure the S3 lifecycle policy to move the backup from the standard to another storage class. After ten days of creating a database, we can move the MariaDB backup to the Glacier deep archive for cost-effectiveness. Log in to the AWS Console, go to the S3 service, enter your bucket, select the management tab, and click on the Create lifecycle rule.
Step 6
Enter the Lifecycle rule name, enter prefix if you have one, select Move current versions of objects between storage classes, select Glacier Deep Archive under Choose storage class transitions, enter 10 in Days after object creation, and acknowledge it.
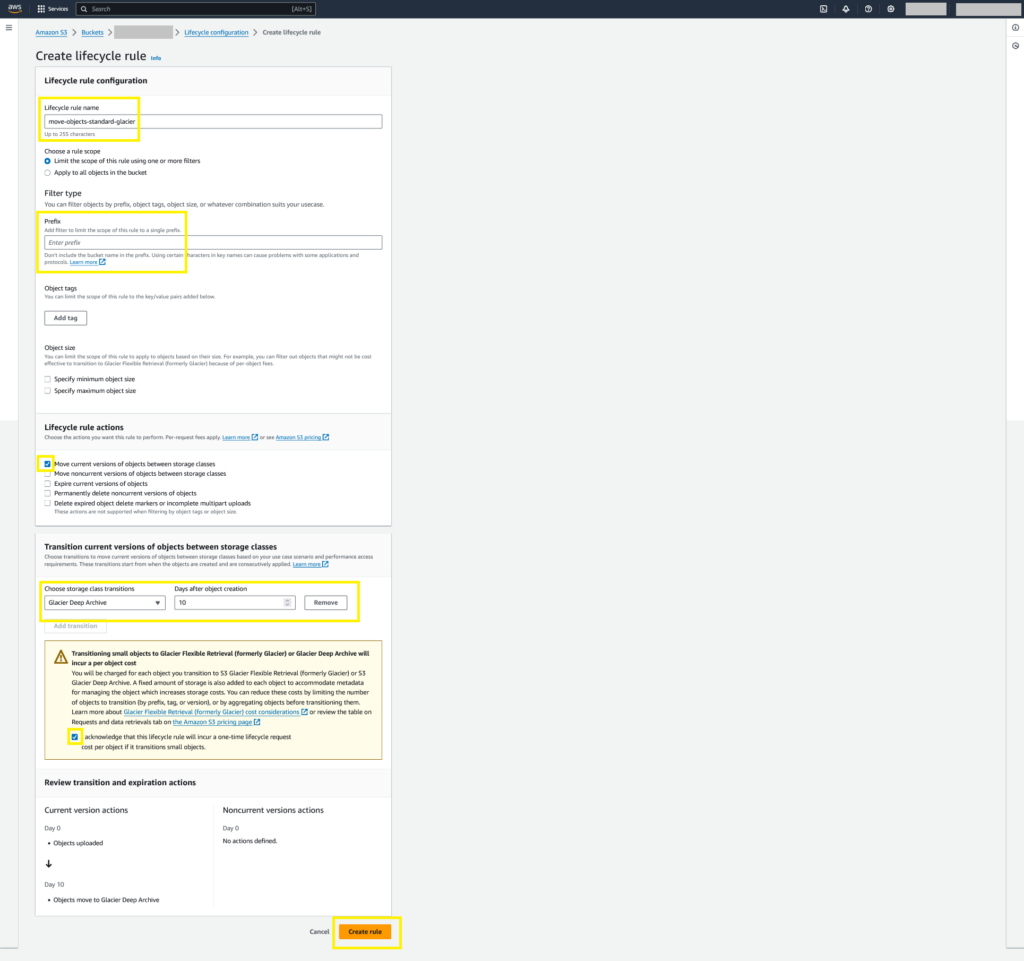
Backups will be stored in the standard storage class for up to 10 days. In case of a sudden need for restoration, there’s no need to wait hours because Amazon S3 Glacier Deep Archive offers two retrieval options with retrieval times ranging from 12 to 48 hours (about 2 days). Backups over ten days will automatically transition to the Glacier Deep Archive storage class.
Step 7
Execute the provided command to restore the backup within your MariaDB pod, facilitating data recovery and maintaining database consistency in the event of data loss or corruption.
kubectl exec <mariadb-pod-name> -n <namespace> — mysql -u <db-username> -p<db-password> <db-name> < <backup-name>.sql
By following these steps, you can effectively back up MariaDB running in an EKS cluster pod and upload it to an S3 bucket for safekeeping and disaster recovery.
Wrapping Up
Securely backing up MariaDB databases from Amazon EKS to low-cost Amazon S3 storage provides a robust data protection and disaster recovery solution. By leveraging AWS CLI and Kubernetes tools, we’ve demonstrated how to configure backups, push them to S3, and manage their lifecycle efficiently. Utilizing S3’s storage classes, such as Glacier Deep Archive, ensures cost-effectiveness without compromising data availability. This setup safeguards your data against potential losses and enables quick and reliable restoration when needed, making it an essential strategy for maintaining data integrity and continuity in cloud environments.