Density-Based Spatial Clustering of Applications with Noise (DBSCAN) is an unsupervised clustering algorithm used to group data points while also identifying outliers, also known as noise.
One of the most significant advantages of a DBSCAN algorithm compared to other algorithms is its ability to find clusters of arbitrary shape. That means, unlike methods such as K-Means Clustering, DBSCAN isn’t limited to conventional circular-shaped clusters and can find groupings in various shapes, including those of a snake, spiral, or donut.
Breaking it Down
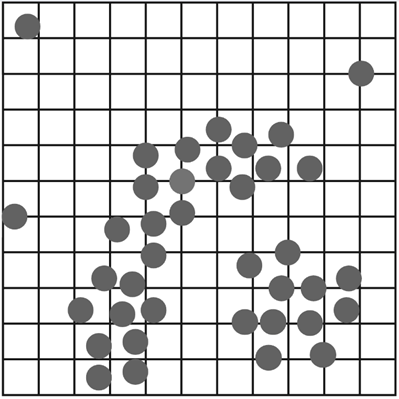
Look at the points on this plot. Just by looking at it, you can probably spot a few clumps that seem to form natural clusters. Also, you might notice some points that are way farther than everything else.
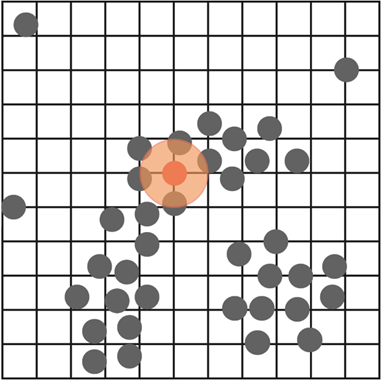
Now, we’ll draw a circle around one of these points. This circle is called an epsilon. In real situations, you get to choose how big this circle is, which can take time, as you would need to try different sizes to see what works best. This point is referred to as a core point. In this example, a core point is any point that has four or more other points touching its epsilon circle. But just like the epsilon size, this number is something you can choose yourself. It could be 8, 3, or 1000. It’s all user-defined.
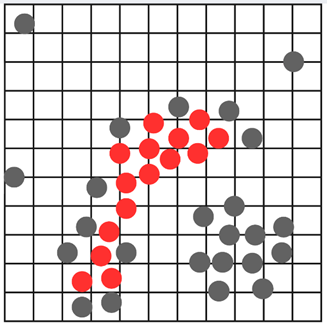
Next, we’ll repeat this process for every other point to check if it’s a core point and label the core points in red.
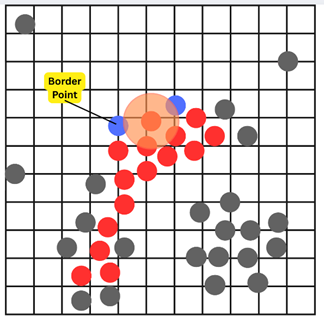
Now that we’ve found the core points, we’ll label the border points. Border points are inside the epsilon of a core point, but don’t have enough neighbors to be core points themselves. We’ll include these border points in the same cluster as the nearby core points.
Next, we’ll repeat this process for the other cluster. Points that belong to the same cluster will be shown in the same color, while points that don’t belong to any cluster will be shown in gray.
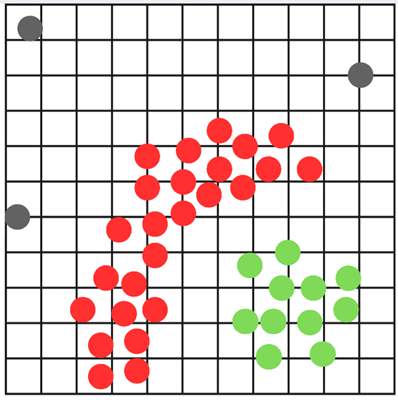
The remaining points that are not in a cluster are considered the outliers or “the noise.”
If this process seems lengthy or time-consuming, don’t worry. Later in this blog, we’ll walk through a Python demo that shows you how to automate it with code.
Real World Use Cases
DBSCAN is widely used across various modern industries for tasks such as pattern recognition, anomaly detection, and spatial analysis. For example, it’s commonly used in cybersecurity for detecting anomalies in network traffic. It clusters typical user behavior, such as login times or session lengths, while labeling unusual activity as outliers. These outliers may represent malware, port scans, or compromised accounts. Because DBSCAN does not require a set number of clusters and handles noise well, it is highly effective for analyzing complex, high-volume security logs.
In healthcare, DBSCAN is used to group patients with similar symptoms, lab results, or treatment responses. It can also identify rare cases that do not fit any cluster, which might signal early complications or special medical needs. This supports better patient profiling and contributes to personalized medicine.
Transportation and logistics companies apply DBSCAN to GPS data to discover common routes or pickup locations. It can also highlight unusual travel paths that suggest delays or unauthorized movement. This makes it valuable for route planning, fleet management, and analyzing traffic patterns.
Let’s Try it in Python
We’re going to walk through how to automate DBSCAN with Python. We’ll use Google Colab to run Python because it’s a beginner-friendly, accessible, and powerful Jupyter-style notebook. For this demo, we’ll work with a synthetic dataset that simulates Wi-Fi signal measurements around a central router.
Step 1: Import Dependencies
First, we’re going to import the necessary tools: pandas to load and work with CSV data, the DBSCAN clustering algorithm from sklearn, and matplotlib.pyplot for creating plots.
import pandas as pd
from sklearn.cluster import DBSCAN
import matplotlib.pyplot as plt
import numpy as npNext, we’ll import the CSV file. Copy the file path and paste it into the line of code.
df = pd.read_csv("**PASTE PATH HERE**")
Step 2: Prepare Input Data
After that, we’ll select our input values for DBSCAN, which will be the X_meters and Y_meters columns from the dataset.
X = df[['X_meters', 'Y_meters']].valuesThen, we’ll pass those values into the DBSCAN function, setting the epsilon to 0.3 and the minimum number of neighbors required to form a core point to 8.
db = DBSCAN(eps=0.3, min_samples=8)
labels = db.fit_predict(X)Step 3: Plotting What We Have
Finally, we’ll plot the data and label everything clearly to create the best possible visualization. Clusters will be displayed in different colors, while outliers will be marked with a black ‘x’.
plt.figure(figsize=(8, 8))
unique_labels = set(labels)
colors = plt.cm.tab10(np.linspace(0, 1, len(unique_labels)))
for label, color in zip(unique_labels, colors):
if label == -1:
color = 'k' # Outliers in black
marker = 'x'
label_text = 'Outliers'
else:
marker = 'o'
label_text = f'Cluster {label}'
mask = (labels == label)
plt.scatter(df.loc[mask, 'X_meters'], df.loc[mask, 'Y_meters'],
c=[color], marker=marker, edgecolors='k', label=label_text, s=20)
plt.title("DBSCAN Clusters from CSV Data")
plt.xlabel("X (meters)")
plt.ylabel("Y (meters)")
plt.legend()
plt.grid(True)
plt.axis('equal')
plt.show()Your final plot should look like this: a ring-shaped cluster surrounding a concentrated cluster in the center.
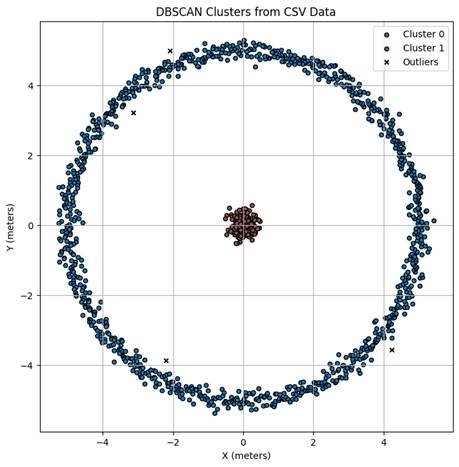
What Are We Looking At?
For this plot, one might imagine that the ring-shaped cluster forms because many WiFi devices tend to be located at a moderate distance from the router, perhaps in surrounding rooms or across an office floor, where the signal strength remains fairly steady but isn’t at its strongest. This would create a circular area of moderate signal strength, resulting in the donut shape.
Meanwhile, the concentration in the center can represent devices very close to the router, such as laptops or phones in the same room, where the signal is likely strongest and less affected by distance. Hypothetically, these two groups reflect how signal strength could vary spatially, producing distinct clusters based on proximity to the router.
Auxin Github
The complete Python notebook for the DBSCAN demo is available for download on our Auxin GitHub repository.
Final Thoughts on DBSCAN Clustering
DBSCAN offers a robust, non-parametric approach to clustering that is well-suited for datasets with noise and clusters of arbitrary shape. Its ability to autonomously identify the number of clusters and classify outliers without relying on centroid-based assumptions makes it particularly effective in real-world scenarios. Whether you’re detecting cyber threats, analyzing patient records, or mapping delivery routes, DBSCAN can reveal meaningful structures in your data.